老刘测评
老刘测评






在信息爆炸的大数据时代,如何以更低成本来解决海量数据的存储问题,已成为企业大数据业务中的重要一环。UCloud自研的新一代对象存储服务US3,在过去一段时间,针对大数据业务场景推出了计算存储分离和大数据备份解决方案。这背后的主要原因包括:
1、由于网络技术的高速发展,使得网络传输性能不再是大数据场景下高吞吐业务需求的瓶颈;
2、Hadoop技术栈中的HDFS存储解决方案运维复杂且成本高昂;
3、云平台基于海量存储资源池构建的对象存储服务US3具备按需使用、操作简单、可靠稳定、价格便宜的优势,是替换HDFS的最佳存储方案选择。
因此,为了让用户能够更加方便的在Hadoop场景下,使用US3实现计算存储分离和大数据备份解决方案,US3自研了US3Hadoop适配器、US3Vmds、US3Distcp三个组件。本文主要介绍US3Hadoop适配器在研发设计过程中的一些思路和问题解决。
总体设计思路
Hadoop生态里对存储的操作基本上都是通过一个通用的文件系统基类FileSystem来进行的。US3Hadoop适配器(简称:适配器)是通过US3FileSystem实现该基类来操作US3。类似于HDFS实现的DistributedFileSystem和基于AWS S3协议实现的S3AFileSystem。适配器直接把IO和索引都请求发给US3,架构如下图所示:
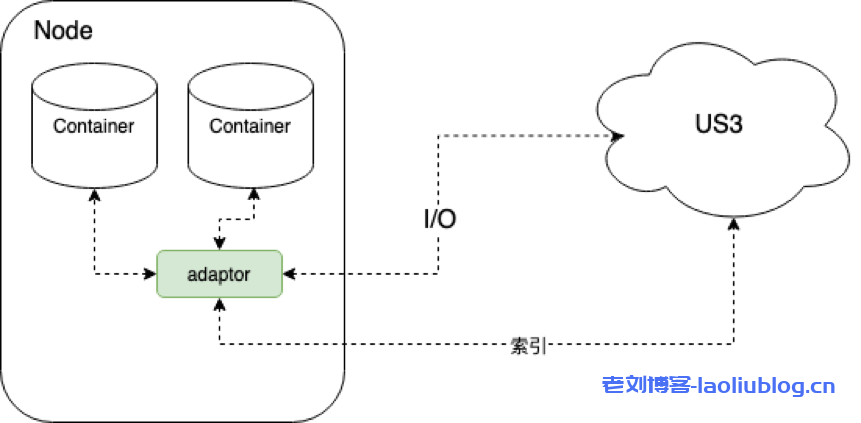
这里的索引操作主要是不涉及读写数据的API,如: HEADFile, ListObjects, Rename, DeleteFile, Copy(用于修改metadata);IO操作的API,如GetFile,PutFile(小于4M文件)已经分片上传相关的4个API: InitiateMultipartUpload,UploadPart,FinishMultipartUpload,AbortMultipartUpload。
US3有了这些API后,怎么跟FileSystem的成员方法能对应起来,可以看下FileSystem需要重写哪些方法。结合实际需求和参考DistributedFileSystem、S3AFileSystem的实现,我们确定了需要重写的主要方法:
initialize、create、rename、getFileStatus、open、listStatus、mkdirs、setOwner、setPermission、setReplication、setWorkingDirectory、getWorkingDirectory、getSchem、getUri、getDefaultBlockSize、delete。同时对一些难以模拟的方法,重写为异常不支持,如Append成员方法。
其实从上面FileSystem的成员方法说明来看,其语义和单机文件系统引擎的接口语义类似,基本上也是以目录树结构来组织管理文件系统。US3提供的ListObjects API刚好也提供了目录树拉取的一种方式,当Hadoop调用listStatus方法时,就可以通过ListObjects循环拉取到当前目录(前缀)下所有子成员从而返回对应的结果。
设置文件所属用户/组,操作权限等相关操作则利用了US3的元数据功能,把这些信息都映射到文件的KV元数据对上。写入文件流则会优先缓存在内存中最多4MB数据,再根据后续的操作来决定采用PutFile还是分片上传的API来实现。
读取文件流则通过GetFile返回流实例来读取期待的数据。虽然这些方法实现看上去很直白,但是潜在着很多值得优化的地方。
getFileStatus的时空博弈
通过分析FileSystem的调用情况,可以知道索引操作在大数据场景中占比达70%以上,而getFileStatus在索引操作重占比最高,所以有必要对其进行优化。那优化点在哪里呢?
首先因为US3中的“目录”(对象存储是KV存储,所谓目录只是模拟而已)是以‘/’结尾的Key,而FileSystem的对文件的操作是通过Path结构进行,该结构的路径都不会以‘/’结尾,所以通过Path拿到的Key去US3中进行HeadFile时,有可能由于该Key在US3中是目录,HeadFile就会返回404, 必须通过第二次用“Key/”去US3中Head才能确认。如果这个Key目录还是不存在,就会导致getFileStatus时延大大增加了。
因此US3适配在创建目录时做了以下两件事:
1.向US3写入mime-type为“file/path”, 文件名为“Key”的空文件;
2.向US3写入mime-type为“application/x-director”, 文件名为“Key/”的空文件;
而普通文件mime-type为“application/octet-stream”。这样在getFileStatus中通过一次HeadFile API就判断当前Key到底是文件还是目录,同时当该目录下为空时,也能在US3控制台展现出该目录。而且由于Hadoop场景写入的主要是大文件,增加一次空文件索引的写入耗时在ms级别,时延基本可忽略。
此外,getFileStatus在Hadoop的使用中具备明显的“时空局部性”特征,在具体的FileSystem实例中最近被getFileStatus操作的Key,在短时间会被多次操作。利用这个特点,US3FileSystem在实现过程中,getFileStatus得到对应的结果在FileStatus返回之前,会把有3s生命周期的FileStatus插入到Cache中。那后续3秒内对该Key的操作就会复用Cache中该Key的FileStatus信息,当然delete操作会在US3中删除完Key后,直接把Cache中的有效FileStatus标记为有3s生命周期的404 Cache,或者直接插入一个有3s生命周期的404 Cache。如果是rename,会复用源的Cache来构造目的Key的Cache,并删除源,这样就能减少大量跟US3的交互。Cache命中(us级别)会减少getFileStatus上百倍的时延。
当然这会引入一定的一致性问题,但仅限于在多个Job并发时至少有一个存在“写”的情况,如delete和rename的情况下,如果仅仅只有读,那么无影响。不过大数据场景基本属于后者。
ListObjects一致性问题
US3的ListObjects接口跟其他对象存储方案类似,目前都只能做到最终一致性(不过US3后续将推出强一致性保证的ListObjects接口),因此其他对象存储实现的适配器也都会存在写入一个文件,然后立即调用listStatus时会偶尔出现这个文件不存在的情况。其他对象存储方案有时会通过引入一个中间件服务(一般是数据库),当写入一个文件会向这个中间件写入这个文件索引,当listStatus时会跟中间件的索引信息进行合并,这样确实缓解了这种情况,进一步提高了一致性。
但还不够,比如写入对象存储成功,但写入中间件时程序奔溃了,这样就导致不一致的问题,又回到了最终一致性的问题。
US3Hadoop适配器的实现相对更加简单有效,不需要借助额外的服务,能提供索引操作级别的Read-Your-Writes一致性,而该一致性级别在Hadoop大部分场景基本等同于强一致性。US3Hadoop适配器不像S3AFileSystem的实现,在create或者rename、delete后立马返回,而是在内部调用ListObjects接口做了一次“对账”,直到“对账”结果符合预期则返回。
当然这里也是有优化空间的,比如delete一个目录时,对应会把这个目录下所有文件先拉出来,然后依次调用DeleteFile API去删除,如果每次DeleteFile API删除都“对账”一次,那么整个时延会翻倍。US3Hadoop适配器的做法是只对最后一次索引操作进行“对账”,这是由于索引的oplog是按时序同步到列表服务中,如果最后一条索引“对账”成功,那么前面的oplog一定在列表服务中写入成功。
Rename的深度定制
前面提到的rename也是US3的一个重要优化点,其他对象存储方案的实现一般通过Copy的接口会先把文件复制一遍,然后再删除源文件。可以看出如果rename的文件很大,那么rename的整个过程势必导致时延很高。
US3根据该场景的需求,专门开发了Rename的API接口,因此US3Hadoop适配器实现rename的语义相对比较轻量,而且时延保持在ms级别。
保证read高效稳定
读是大数据场景的高频操作,所以US3Hadoop适配器的读取流实现,不是对http响应的body简单封装,而是考虑了多方面的优化。例如,对读取流的优化,通过加入预读Buffer,减少网络IO系统调用频率,降低read操作的等待时延,特别是大批量顺序读的IO提升效果明显。
另外,FileSystem的读取流具有seek接口,也就是需要支持随机读,这里又分两种场景:
1、seek到已读流位置的前置位置,那么作为Underlay Stream的Http响应的body流就要作废关闭掉,需要重新发起一个从seek的位置开始分片下载的GetFile API,获得其Http响应的body流来作为新的Underlay Stream。但是实际测试过程中发现,很多seek操作过后不一定会进行read操作,有可能直接关闭,或者seek回到已读取流位置的后置位置,所以在seek发生时,US3Hadoop适配器的实现是只做seek位置标记,在read的时候根据实际情况对Underlay Stream做延迟关闭打开处理。此外如果seek的位置还在Buffer中,也不会重新打开Underlay Stream,而是通过修改Buffer的消费偏移。
2、随机读的另一种场景就是,seek到已读流位置的后置位置。这里同样跟前面一样采用延迟流打开,但是在确定要做真实的seek操作时,不一定会通过关闭老的Underlay Stream,重新在目标位置打开新的Underlay Stream来实现。因为当前已读的位置跟seek的后置位置可能距离很近,假设只有100KB距离,说不定这段距离完全在预读Buffer的范围中,这时也可以通过修改Buffer的消费偏移来实现。
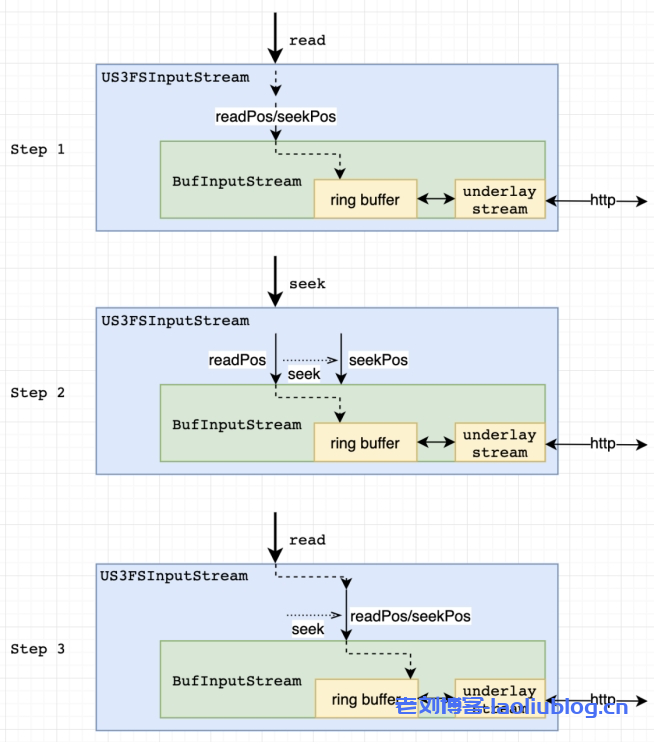
事实上US3Hadoop适配器确实也是这么做的,不过目前的规则是seek的后置位置到当前已读流位置的距离小于等于预读Buffer剩余空间加上16K的和,则直接通过修改预读Buffer的消费偏移和消费Underlay Stream中的数据来定位到seek的后置位置上。之所以还加了16K是考虑到TCP接收缓存中的数据。当然后续确定从一个ready的Underlay Stream中消费N字节数据的时间成本大致等于重新发起一个GetFile API并在准备传输该Http响应body之前的时间成本,也会考虑把这N字节的因素计入偏移计算过程中。
最后流的优化还要考虑到Underlay Stream异常的情况,比如HBase场景长时间持有打开的流,却由于其他操作导致长时间没有操作该流,那么US3可能会主动关闭释放Underlay Stream对应的TCP连接,后续对在Underlay Stream上的操作就会报TCP RST的异常。为了提供可用性,US3Hadoop适配器的实现是在已经读取位置点上进行Underlay Stream的重新打开。
写在最后
US3Hadoop适配器的实现在借鉴开源方案下,进一步优化了相关核心问题点,提升了Hadoop访问US3的可靠性与稳定性,并在多个客户案例中发挥着打通Hadoop与US3的重要桥梁作用,帮助用户提升大数据场景下的存储读写效率。
但US3Haoop适配器还存在很多可提升的空间,相比于HDFS,索引、IO的时延还有差距,原子性保障上也相对比较弱,这些也是我们接下来要思考解决的问题。目前推出的US3Vmds解决了索引时延的大部分问题,使得通过US3Hadoop适配器操作US3的性能得到大幅提升,并在部分场景接近原生HDFS的性能。具体数据可以参考官方文档(https://docs.ucloud.cn/ufile/tools/us3vmds/testdata?id=%e6%b5%8b%e8%af%95%e6%95%b0%e6%8d%ae)。
未来,US3产品会不断改进优化大数据场景下的存储解决方案,在降低大数据存储成本的同时,进一步提升用户在大数据场景下的US3使用体验。