老刘测评
老刘测评






为了解决在数据备份场景中的可靠性、容量、成本问题,越来越多的用户倾向于使用对象存储来进行备份。然而,有些场景下通过对象存储US3来备份还是不够方便,甚至不适用。比如在数据库备份场景下,如果直接使用对象存储备份,可能需要先把数据库通过mysqldump做逻辑备份,或者采用xtrabackup做物理备份到本地,然后使用基于对象存储的SDK的工具把备份文件上传到对象存储,备份过程繁琐。再例如服务的日志归档备份,为降低成本可以将日志存储到对象存储US3中,通过SDK或者工具来操作,不仅需要编写备份代码,而且管理复杂。如果能提供一种以POSIX接口远程访问对象存储的方式,就可以很好地解决上述问题。
UCloud对象存储产品US3:20GB免费云存储空间和20GB/月免费下载流量(对比了七牛云、又拍云、腾讯云、猫云,UCloud的免费额度给的最大的了,同时单价0.004元/GB/天(不区分存储和下载流量定价,同价计费)也是最便宜的,用量大的话都是可以申请更低折扣的,US3产品页>>
对象存储挖矿方案:《用对象存储挖矿教程:不用买硬盘!来看下AWS推出的Chia奇亚币云挖矿解决方案》
开源方案实践
已经有一些开源的项目将对象存储中的bucket映射为文件系统,如s3fs和goofys等,在使用这些开源方案的时候,我们发现了一些问题。
s3fs
s3fs通过FUSE将s3和支持s3协议的对象存储的bucket挂载到本地(FUSE的介绍详见下文)。通过对s3fs进行测试后,我们发现其在大文件的写入方面性能特别差,研究其实现过程后,我们发现s3fs在写入时会优先写入本地临时文件,然后以分片上传的方式将并发的将数据写入到对象存储。如果空间不足,则会以同步的方式将分片上传,代码如下:
ssize_t FdEntity::Write(const char* bytes, off_t start, size_t size) { // no enough disk space if(0 != (result = NoCachePreMultipartPost())){ S3FS_PRN_ERR("failed to switch multipart uploading with no cache(errno=%d)", result); return static_cast(result); } // start multipart uploading if(0 != (result = NoCacheLoadAndPost(0, start))){ S3FS_PRN_ERR("failed to load uninitialized area and multipart uploading it(errno=%d)", result); return static_cast(result); } }
由于我们的主要使用场景为大文件的备份,基于云主机硬盘成本等方面的考虑,我们决定放弃这一方案。
goofys
goofys是用go实现的将s3以及部分非s3协议的对象存储挂载到linux的文件系统,测试后,我们发现goofys主要有三个问题:
写入没有进行并发控制。在大文件的写入场景下,goofys同样将文件进行分片,然后每个分片开一个协程写入到后端存储。对象存储一般通过HTTP协议进行通信,由于请求是同步的方式,在不限制并发数的情况下会有大量的连接,消耗大量的内存等资源。
读取采用同步方式,性能很差。FUSE有两种读取模式async和sync,通过挂载时的设置去选择,goofys强制使用了sync模式,并且预读的实现为乱序读取超过三次后停止预读,代码如下:
if !fs.flags.Cheap && fh.seqReadAmount >= uint64(READAHEAD_CHUNK) && fh.numOOORead < 3 { ... err = fh.readAhead(uint64(offset), len(buf)) ... }
fh.numOOORead为乱序读取的次数,FUSE模块会对超过128k的IO进行拆分,以128k对齐。简单介绍一下FUSE的同步读取和异步读取模式的区别。内核的读取一般入口是在底层文件系统的read_iter函数,然后调用VFS层的generic_file_read_iter,该函数内部实现会通过调用readpages进行预读。如果预读后没有对应的page则会调用readpage读取单页。由于goofys不支持该设置,我们通过对s3fs设置不同的配置来测试,然后抓取读取时的调用栈对比其中的区别。设置了异步读取模式的读堆栈如下所示:
fuse_readpages+0x5/0x110 [fuse] read_pages+0x6b/0x190 __do_page_cache_readahead+0x1c1/0x1e0 ondemand_readahead+0x1f9/0x2c0 ? pagecache_get_page+0x30/0x2d0 generic_file_buffered_read+0x5a50xb10 ? mem_cgroup_try_charge+0x8b/0x1a0 ? mem_cgroup_throttle_swaprate+0x17/0x10e fuse_file_read_iter+0x10d/0x130 [fuse] ? __handle_mm_fault+0x662/0x6a0 new_sync_read+0x121/0x170 vfs_read+0x91/0x140
其中vfs_read是系统调用到vfs层的入口函数。之后会调用到readpages进行多页的读取。fuse_readpages将读请求发给用户态文件系统,进而完整整个读取流程。同步读取模式的堆栈如下所示:
fuse_readpage+0x5/0x60 [fuse] generic_file_buffered_read+0x61a/0xb10 ? mem_cgroup_try_charge+0x8b/0x1a0 ? mem_cgroup_throttle_swaprate+0x17/0x10e fuse_file_read_iter+0x10d/0x130 [fuse] ? __handle_mm_fault+0x662/0x6a0 new_sync_read+0x121/0x170 vfs_read+0x91/0x140
和异步流程相同,依然是在generic_file_read_iter中进行读取,当读取之后没有对应的页,会尝试读取单页。相关代码如下,内核版本基于4.14:
no_cached_page: /* * Ok, it wasn't cached, so we need to create a new * page.. */ page = page_cache_alloc_cold(mapping); if (!page) { error = -ENOMEM; goto out; } error = add_to_page_cache_lru(page, mapping, index, mapping_gfp_constraint(mapping, GFP_KERNEL)); if (error) { put_page(page); if (error == -EEXIST) { error = 0; goto find_page; } goto out; } goto readpage;
如果设置了同步方式进行读取,FUSE模块会无效内核的预读,转而进入到no_cached_page读取单页。所以同步模式下落到用户态文件系统的读IO有大块的readpagesIO和readpage的4K单页IO,由于offset存在相同,goofys会判断为乱序的读取,超过3次后停止预读,由于每次和US3的交互都是4K的GET请求,性能会比较差,难以满足用户的需求。
分片上传的大小不固定,无法适配US3 。US3目前的分片大小固定为4M,而goofys的分片大小需要动态的去计算,并手动修改进行适配,代码如下:
func (fh *FileHandle) partSize() uint64 { var size uint64 if fh.lastPartId < 1000 { size = 5 * 1024 * 1024 } else if fh.lastPartId < 2000 { size = 25 * 1024 * 1024 } else { size = 125 * 1024 * 1024 } ... }
同时,s3协议本身没有rename的的接口,s3fs和goofys的rename都是通过将源文件内容复制到目标文件,然后删除源文件实现的。
而US3内部支持直接修改文件名,US3FS通过使用相关的接口实现rename操作,相比s3fs和goofys性能更好。同时s3fs和goofys挂载US3的bucket都需要走代理进行协议的转换,使用US3FS则减少了这一IO路径,性能上更有优势。
通过对s3fs和goofys的实践,我们发现两者在US3的备份场景上的性能有一些问题,同时适配的工作量也比较大,基于此,我们决定开发一款能够满足用户在数据备份场景需求的,依托对象存储作为后端的文件系统。
US3FS设计概述
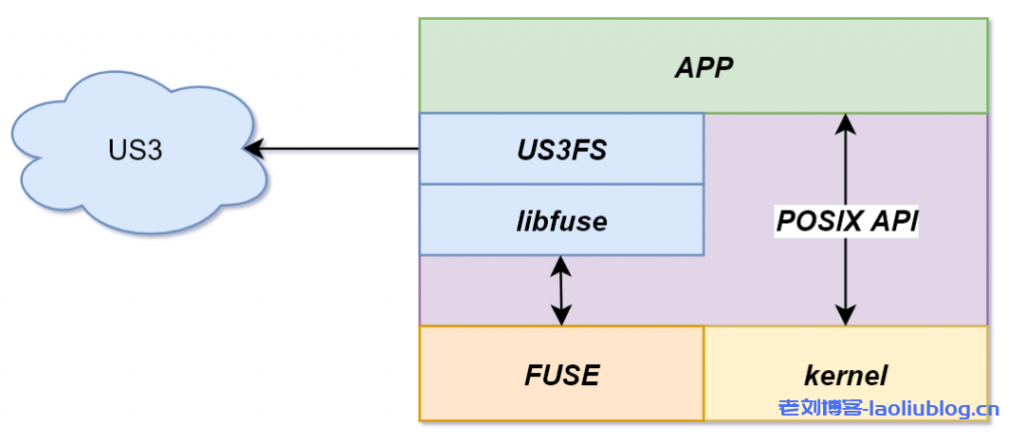
US3FS通过FUSE实现部分POSIX API。在介绍US3FS实现之前,先简单介绍一下Linux的VFS机制和FUSE实现(有这部分基础的朋友可直接跳过)。
VFS
VFS,全称Virtual File System,是linux内核中一个承上启下的虚拟层,隶属于IO子系统。对上,为用户态应用提供了文件系统接口;对下,将具体的实现抽象为同一个函数指针供底层文件系统实现。
linux文件系统中的元数据分为dentry(directory entry)和inode,我们知道,文件名并不属于文件的元数据,为了优化查询,vfs在内存中建立dentry以缓存文件名和inode的映射以及目录树的实现。单机文件系统的实现,dentry只存在于内存中,不会落盘,当查找某个文件时内存没有对应的dentry,vfs会调用具体的文件系统实现来查找对应的文件,并建立起对应的数据结构。inode缓存了一个文件的元数据,如大小,修改时间等,会持久化到硬盘中,数据的读写通过地址空间找到对应的page和block device进行读写。
FUSE
FUSE,全称Filesystem in Userspace,用户态文件系统,我们知道,一般直接在内核态实现某个特性是比较痛苦的事情,通常内核的debug比较困难,而且稍不注意就会陷入到内核的各种细节而无法自拔。FUSE就是为了简化程序员的工作,将内核的细节隐藏起来,提供一套用户态的接口用于实现自己的文件系统,用户只需要实现对应的接口即可。内核态的FUSE模块和用户态的FUSE库的交互通过/dev/fuse进行通信,然后调用用户自己的实现。当然,缺点就是增加了IO路径以及内核态/用户态的切换,对性能有一定影响。
元数据设计
US3FS通过实现FUSE的接口,将US3中bucket的对象映射为文件,和分布式文件系统不同,没有mds(metadata server)维护文件元数据,需要通过HTTP向us3获取。当文件较多时,大量的请求会瞬间发出,性能很差。为了解决这一点,US3FS在内存中维护了bucket的目录树,并设置文件元数据的有效时间,避免频繁和US3交互。
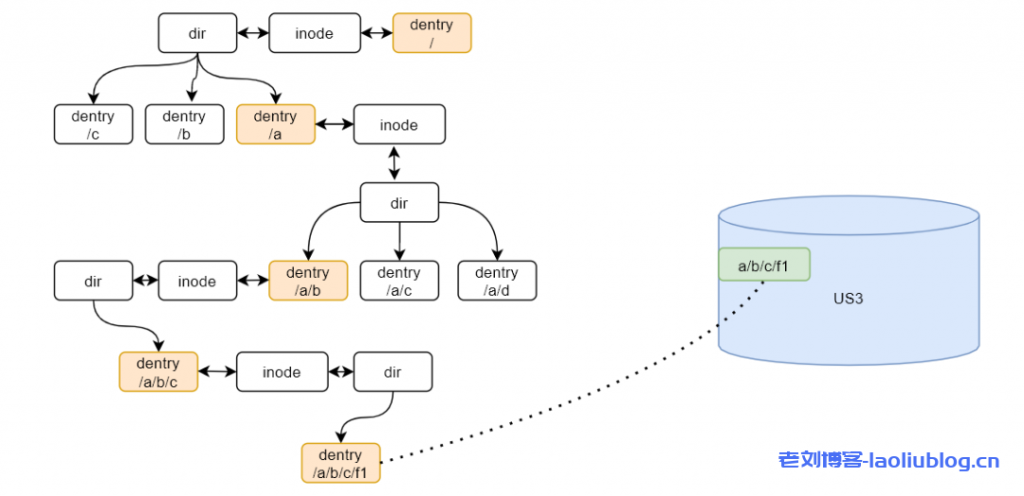
这也带来了一致性的问题,当多个client修改同一bucket中的文件,其中的缓存一致性无法保证,需要用户自己取舍。为了提升检索的性能,文件并没有像对象存储以平铺的方式放在整个目录中,而是采用了传统文件系统类似的方式,为每一个目录构建相关数据结构来保存其中的文件,同时inode的设计也尽量简洁,只保存必要字段,减少内存的占用。
目前Inode中保存的字段有uid,gid,size,mtime等,通过US3的元数据功能在对象中持久化。例如下图所示,在US3的bucket中有一个名为”a/b/c/f1″的对象,在文件系统中,会将每一个“/”划分的前缀映射为目录,从而实现左边的目录树。
IO流程设计
对于数据的写入,US3支持大文件的分片上传。利用这一特性,US3FS通过将数据写入cache,在后台将数据以分片上传的方式,将数据以4MB的chunk写入到后端存储中。分片上传的流程如下图所示,通过令牌桶限制整个系统的写入并发数。每个分片写入的线程都会获取令牌后写入,通过当文件close时写入最后一个分片,完成整个上传流程。
文件的读取通过在US3FS的cache实现预读来提升性能。kernel-fuse自身对数据的读写进行了分片,在不修改内核的情况下,IO最大为128K。而大文件的读取场景一般为连续的大IO,这种场景下IO会被切成128K的片,不做预读的话,无法很好的利用网络带宽。US3FS的预读算法如下所示:
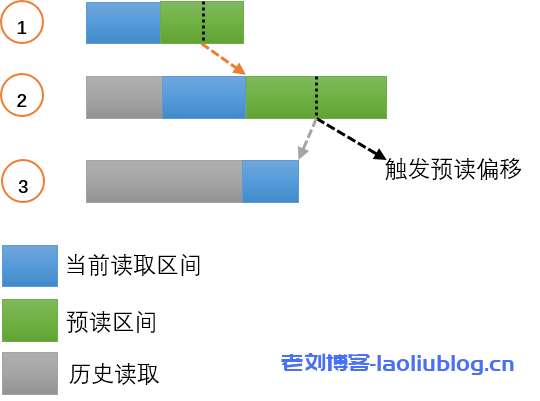
如图所示,第一次同步读取完成后,会往后进行当前长度的预读,并将预读的中点设置为下次触发预读的trigger。之后的读取如果不连续,则清空之前的状态,进行新的预读,如果连续,则判断当前读取的结束位置是否不小于触发预读的偏移,如果触发预读,则将预读窗口的大小扩大为2倍,直到达到设定的阈值。之后以新的窗口进行预读。如果未触发,则不进行预读。预读对顺序读的性能有很大提升。鉴于US3FS使用场景多为大文件的场景,US3FS本身不对数据进行任何缓存。在US3FS之上有内核的pagecache,当用户重复读取同一文件时pagecache能够很好的起作用。
数据一致性
由于对象存储的实现机制原因,当前大文件的写入,在完成所有的分片上传之前,数据是不可见的,所以对于US3FS的写入,在close之前,写入的数据都是不可读的,当close后,US3FS会发送结束分片的请求,结束整个写入流程,此时数据对用户可见。
对比测试
在并发度为64,IO大小为4M测试模型下,40G文件的顺序写和顺序读进行多次测试,平均结果如下:
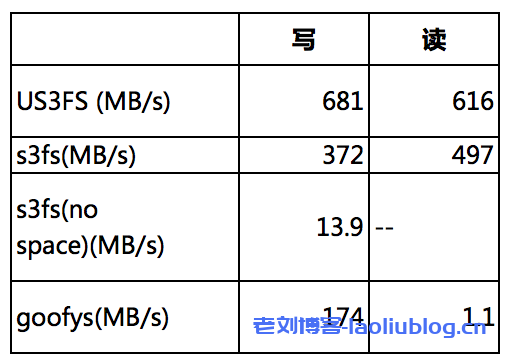
测试过程中,goofys的内存占用比较高,峰值约3.3G,而US3FS比较平稳,峰值约305M,节省了90%内存空间。s3fs表现相对较好,因为使用本地临时文件做缓存,所以内存占用比较少,但是写入文件比较大,硬盘空间不足时,性能会下降到表格中的数据。
在顺序读的测试中,测试结果可以验证我们的分析,goofys由于本身设计的原因,在这种场景下性能无法满足我们的要求。另外在测试移动1G文件的场景中,对比结果如下:
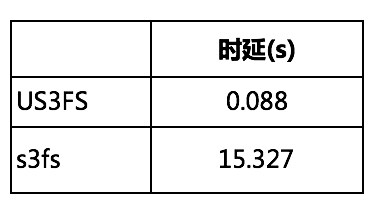
可见在移动需求场景下,特别是大文件居多的场景,通过US3FS能提升上百倍的性能。
总而言之,s3fs和goofys在大文件的读写场景下各有优劣,相比之下,US3自研的 US3FS 无论是读还是写都有更好的性能,而且和US3的适配性更强,更易于拓展。
UCloud对象存储产品US3:20GB免费云存储空间和20GB/月免费下载流量(对比了七牛云、又拍云、腾讯云、猫云,UCloud的免费额度给的最大的了,同时单价0.004元/GB/天(不区分存储和下载流量定价,同价计费)也是最便宜的,用量大的话都是可以申请更低折扣的,US3产品页>>