老刘测评
老刘测评








2021年12月23日,AWS的其中一个数据中心遭遇了故障,这已是该公司在本月的第三次中断事件。
今天早上,AWS US-EAST-1区域的停电影响了Slack、Asana、Epic Games及其他众多服务。
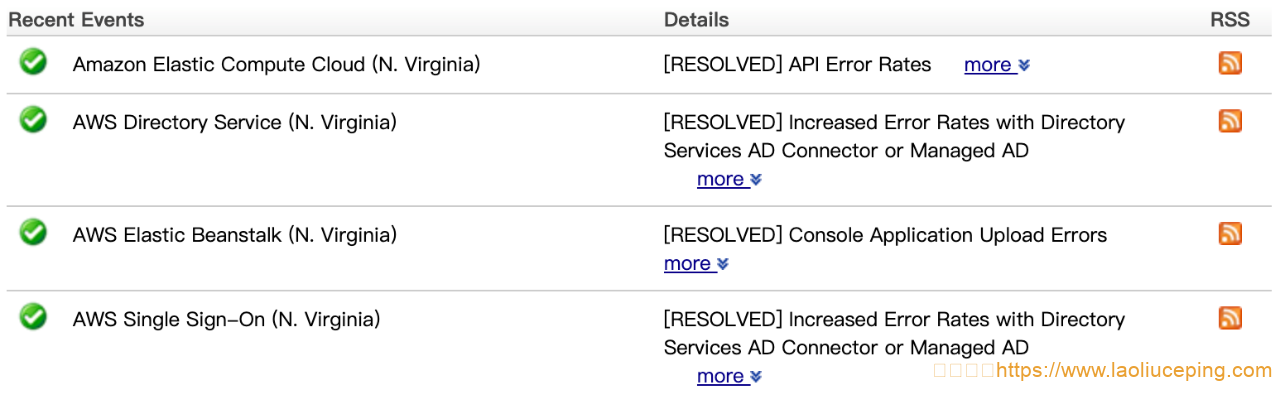
问题是从美国东部时间上午7点30左右开始的;到下午1点,这些问题产生的一系列连锁反应继续困扰着诸多服务,AWS继续报告该区域的许多服务存在问题,具体来说是其EC2计算服务及相关网络功能。
该地区的单点登录服务也开始出现了错误率增加的情况。
AWS在美国东部时间上午8点的更新中解释道:“我们可以确认,US-EAST-1区域的单个可用区(USE1-AZ4)内的一个数据中心遭遇了断电。这影响到EC2实例的可用性和连接,这些实例是受影响的可用区内那个受影响数据中心的一部分。我们还遇到了受影响的可用区内启动的RunInstance API错误率增加的情况。与受影响可用区内或US-EAST-1区域内其他可用区内的其他数据中心的连接和电源则没有受到该问题的影响,但我们建议借助故障切换机制,远离受影响的可用区(USE1-AZ4),如果您有能力这么做的话。”
如果说这是AWS近几周唯一的一起故障,几乎不会引起注意。但考虑到现代超级云具有的复杂性,故障难免时不时会发生。但目前AWS每周却要发生一次故障,频繁程度实属罕见。
12月7日,同一个 US-EAST-1区域因网络问题而宕机了数小时。
12月17日,影响AWS两个西海岸区域之间连接的中断导致了Netflix、Slack及亚马逊自己的Ring等服务随之瘫痪。
雪上加霜的是,所有这些故障都是在AWS于本月早些时候的re:Invent大会上吹嘘其云弹性有多佳之后出现的,真是打脸啪啪响。
当然在理想情况下,这些故障根本不会发生,AWS用户有一些方法可以通过设计系统架构,出现故障后切换到另一个地区,从而保护自己远离这些故障——但这么做会大大增加成本,因此有人认定不值得在停运时间和成本之间作一折中考虑。
归根结底,AWS有义务提供一套稳定的平台。虽然很难说到底是这家公司只是运气不好,还是说存在任何系统性的问题,因而导致了这些问题,但如果现在我在US-EAST-1区域托管服务,我可能会起码考虑将该服务移到别处。
AWS故障说明
4:35 AM PST We are investigating increased EC2 launch failures and networking connectivity issues for some instances in a single Availability Zone (USE1-AZ4) in the US-EAST-1 Region. Other Availability Zones within the US-EAST-1 Region are not affected by this issue.5:01 AM PST We can confirm a loss of power within a single data center within a single Availability Zone (USE1-AZ4) in the US-EAST-1 Region. This is affecting availability and connectivity to EC2 instances that are part of the affected data center within the affected Availability Zone. We are also experiencing elevated RunInstance API error rates for launches within the affected Availability Zone. Connectivity and power to other data centers within the affected Availability Zone, or other Availability Zones within the US-EAST-1 Region are not affected by this issue, but we would recommend failing away from the affected Availability Zone (USE1-AZ4) if you are able to do so. We continue to work to address the issue and restore power within the affected data center.5:18 AM PST We continue to make progress in restoring power to the affected data center within the affected Availability Zone (USE1-AZ4) in the US-EAST-1 Region. We have now restored power to the majority of instances and networking devices within the affected data center and are starting to see some early signs of recovery. Customers experiencing connectivity or instance availability issues within the affected Availability Zone, should start to see some recovery as power is restored to the affected data center. RunInstances API error rates are returning to normal levels and we are working to recover affected EC2 instances and EBS volumes. While we would expect continued improvement over the coming hour, we would still recommend failing away from the Availability Zone if you are able to do so to mitigate this issue.5:39 AM PST We have now restored power to all instances and network devices within the affected data center and are seeing recovery for the majority of EC2 instances and EBS volumes within the affected Availability Zone. Network connectivity within the affected Availability Zone has also returned to normal levels. While all services are starting to see meaningful recovery, services which were hosting endpoints within the affected data center – such as single-AZ RDS databases, ElastiCache, etc. – would have seen impact during the event, but are starting to see recovery now. Given the level of recovery, if you have not yet failed away from the affected Availability Zone, you should be starting to see recovery at this stage.6:13 AM PST We have now restored power to all instances and network devices within the affected data center and are seeing recovery for the majority of EC2 instances and EBS volumes within the affected Availability Zone. We continue to make progress in recovering the remaining EC2 instances and EBS volumes within the affected Availability Zone. If you are able to relaunch affected EC2 instances within the affected Availability Zone, that may help to speed up recovery. We have a small number of affected EBS volumes that are still experiencing degraded IO performance that we are working to recover. The majority of AWS services have also recovered, but services which host endpoints within the customer’s VPCs – such as single-AZ RDS databases, ElasticCache, Redshift, etc. – continue to see some impact as we work towards full recovery.6:51 AM PST We have now restored power to all instances and network devices within the affected data center and are seeing recovery for the majority of EC2 instances and EBS volumes within the affected Availability Zone. For the remaining EC2 instances, we are experiencing some network connectivity issues, which is slowing down full recovery. We believe we understand why this is the case and are working on a resolution. Once resolved, we expect to see faster recovery for the remaining EC2 instances and EBS volumes. If you are able to relaunch affected EC2 instances within the affected Availability Zone, that may help to speed up recovery. Note that restarting an instance at this stage will not help as a restart does not change the underlying hardware. We have a small number of affected EBS volumes that are still experiencing degraded IO performance that we are working to recover. The majority of AWS services have also recovered, but services which host endpoints within the customer’s VPCs – such as single-AZ RDS databases, ElasticCache, Redshift, etc. – continue to see some impact as we work towards full recovery.8:02 AM PST Power continues to be stable within the affected data center within the affected Availability Zone (USE1-AZ4) in the US-EAST-1 Region. We have been working to resolve the connectivity issues that the remaining EC2 instances and EBS volumes are experiencing in the affected data center, which is part of a single Availability Zone (USE1-AZ4) in the US-EAST-1 Region. We have addressed the connectivity issue for the affected EBS volumes, which are now starting to see further recovery. We continue to work on mitigating the networking impact for EC2 instances within the affected data center, and expect to see further recovery there starting in the next 30 minutes. Since the EC2 APIs have been healthy for some time within the affected Availability Zone, the fastest path to recovery now would be to relaunch affected EC2 instances within the affected Availability Zone or other Availability Zones within the region.9:28 AM PST We continue to make progress in restoring connectivity to the remaining EC2 instances and EBS volumes. In the last hour, we have restored underlying connectivity to the majority of the remaining EC2 instance and EBS volumes, but are now working through full recovery at the host level. The majority of affected AWS services remain in recovery and we have seen recovery for the majority of single-AZ RDS databases that were affected by the event. If you are able to relaunch affected EC2 instances within the affected Availability Zone, that may help to speed up recovery. Note that restarting an instance at this stage will not help as a restart does not change the underlying hardware. We continue to work towards full recovery.11:08 AM PST We continue to make progress in restoring power and connectivity to the remaining EC2 instances and EBS volumes, although recovery of the remaining instances and volumes is taking longer than expected. We believe this is related to the way in which the data center lost power, which has led to failures in the underlying hardware that we are working to recover. While EC2 instances and EBS volumes that have recovered continue to operate normally within the affected data center, we are working to replace hardware components for the recovery of the remaining EC2 instances and EBS volumes. We have multiple engineers working on the underlying hardware failures and expect to see recovery over the next few hours. As is often the case with a loss of power, there may be some hardware that is not recoverable, and so we continue to recommend that you relaunch your EC2 instance, or recreate you EBS volume from a snapshot, if you are able to do so.12:03 PM PST Over the last hour, after addressing many of the underlying hardware failures, we have seen an accelerated rate of recovery for the affected EC2 instances and EBS volumes. We continue to work on addressing the underlying hardware failures that are preventing the remaining EC2 instances and EBS volumes. For customers that continue to have EC2 instance or EBS volume impairments, relaunching affected EC2 instances or recreating affecting EBS volumes within the affected Availability Zone, continues to be a faster path to full recovery.1:39 PM PST We continue to make progress in addressing the hardware failures that are delaying recovery of the remaining EC2 instances and EBS volumes. At this stage, if you are still waiting for an EC2 instance or EBS volume to fully recover, we would strongly recommend that you consider relaunching the EC2 instance or recreating the EBS volume from a snapshot. As is often the case with a loss of power, there may be some hardware that is not recoverable, which will prevent us from fully recovering the affected EC2 instances and EBS volumes. We are not quite at that point yet in terms of recovery, but it is unlikely that we will recover all of the small number of remaining EC2 instances and EBS volumes. If you need help in launching new EC2 instances or recreating EBS volumes, please reach out to AWS Support.3:13 PM PST Since the last update, we have more than halved the number of affected EC2 instances and EBS volumes and continue to work on the remaining EC2 instances and EBS volumes. The remaining EC2 instances and EBS volumes have all experienced underlying hardware failures due to the nature of the initial power event, which we are working to resolve. We expect to make further progress on this list within the next hour, but some of the remaining EC2 instances and EBS volumes may not be recoverable due to hardware failures. If you have the ability to relaunch an affected EC2 instance or recreate an affected EBS volume from snapshot, we continue to strongly recommend that you take that path.4:22 PM PST Starting at 4:11 AM PST some EC2 instances and EBS volumes experienced a loss of power in a single data center within a single Availability Zone (USE1-AZ4) in the US-EAST-1 Region. Instances in other data centers within the affected Availability Zone, and other Availability Zones within the US-EAST-1 Region were not affected by this event. At 4:55 AM PST, power was restored to EC2 instances and EBS volumes in the affected data center, which allowed the majority of EC2 instances and EBS volumes to recover. However, due to the nature of the power event, some of the underlying hardware experienced failures, which needed to be resolved by engineers within the facility. Engineers worked to recover the remaining EC2 instances and EBS volumes affected by the issue. By 2:30 PM PST, we recovered the vast majority of EC2 instances and EBS volumes. However, some of the affected EC2 instances and EBS volumes were running on hardware that has been affected by the loss of power and is not recoverable. For customers still waiting for recovery of a specific EC2 instance or EBS volume, we recommend that you relaunch the instance or recreate the volume from a snapshot for full recovery. If you need further assistance, please contact AWS Support.
12:06 PM PST We continue to investigate increased error rates for some customers using Directory Services AD Connector or Managed AD with Amazon SSO in US-EAST-1 Region. This is also impacting some services, like Amazon WorkSpaces, that can be configured to use Directory Services for user authentication. Some customers may begin to see signs of recovery. Customers using other Active Directory functionality are not impacted at this time.2:29 PM PST We continue to resolve increased error rates for Directory Services AD or Managed AD, impacting some services like Amazon WorkSpaces that can be configured to use Directory Services for user authentication. We are prioritizing the most impacted directories to expedite resolution. Additional customers will see recovery as resolution takes place. Customers using other Active Directory functionality are not impacted at this time.4:09 PM PST Our mitigation efforts are working as expected and we are making steady progress toward recovery of error rates for Directory Services AD or Managed AD, impacting some services like Amazon WorkSpaces that can be configured to use Directory Services for user authentication. We continue to prioritize the most impacted directories to expedite resolution. Additional customers will see recovery as resolution takes place. Customers using other Active Directory functionality are not impacted at this time.5:57 PM PST Between 4:09 AM and 5:00 PM PST we experienced increased error rates for some customers using Directory Services AD Connector or Managed AD with Directory Services in US-EAST-1 Region. This also impacted some services, like Amazon WorkSpaces, that can be configured to use Directory Services for user authentication. The issue has been resolved and the service is operating normally. Customers using other Active Directory functionality were not impacted by this issue. If you experience any issues with this service or need further assistance, please contact AWS Support.
11:33 PM PST We are investigating an issue where customers are unable to upload and deploy new application versions through the Elastic Beanstalk console in multiple Regions. Customers who need to update or deploy a new application version should do so using the AWS CLI. Existing applications are not impacted by this issueDec 22, 12:34 AM PST We continue to investigate an issue where customers are unable to upload and deploy new application versions through the Elastic Beanstalk console in multiple Regions. We are determining the root causes and working through steps to mitigate the issue. Customers who need to update or deploy a new application version should do so using the AWS CLI while we work towards resolving the issue. Existing applications are not impacted by this issue.Dec 22, 1:20 AM PST We have identified the root cause and prepared a fix to address the issue that prevents customers from uploading new application versions through the Elastic Beanstalk console in multiple Regions. The service team is testing this fix and preparing for deployment to the Regions that are affected by this issue. We expect to see full recovery by 3:00 AM PST and will continue to keep you updated if this ETA changes. Customers who need to update or deploy a new application version should do so using the AWS CLI until the issue is fully resolved.Dec 22, 3:21 AM PST Between December 21, 2021 at 6:37 PM and December 22, 2021 at 03:17 AM PST, customers were unable to upload their code through the Elastic Beanstalk console due to a Content Security Policy (CSP) error. Customers were impacted when they attempted to upload a new application version for existing environments or upload their code when creating a new environment in multiple regions. The issue has been resolved and the service is operating normally.
9:26 AM PST We are investigating increased error rates for some customers using Directory Services AD Connector or Managed AD with Amazon SSO in US-EAST-1 Region. Customers using other Active Directory functionality are not impacted at this time.10:49 AM PST We continue to investigate increased error rates for some customers using Directory Services AD Connector or Managed AD with Amazon SSO in US-EAST-1 Region. Some customers may begin to see signs of recovery. Customers using other Active Directory functionality are not impacted at this time.11:56 AM PST We continue to investigate increased error rates for some customers using Directory Services AD Connector or Managed AD with Amazon SSO in US-EAST-1 Region. This is also impacting some services, like Amazon WorkSpaces, that can be configured to use Directory Services for user authentication. Some customers may begin to see signs of recovery. Customers using other Active Directory functionality are not impacted at this time.12:10 PM PST As the root cause of this impact is related to Directory Services, we will continue to provide updates on the new post we have just created for Directory Service in the US-EAST-1 Region.5:56 PM PST Between 4:09 AM and 5:00 PM PST we experienced increased error rates for some customers using Directory Services AD Connector or Managed AD with Amazon SSO in US-EAST-1 Region. The issue has been resolved and the service is operating normally. If you experience any issues with this service or need further assistance, please contact AWS Support.