老刘测评
老刘测评






最近一年,分布式云这个字眼,被太多人提起,简直成了网红。

几乎所有的云巨头,都在猛推这种云计算的新玩法。
AWS整了Outposts,微软云拿出Azure Arc,而谷歌云则有Anthos,虽然叫法不同,形态细节也有区别,但是“内心戏”都大差不差。

大家的目标,就是把自家的公有云,尽最大可能向客户侧延伸。这是分布式云的初衷。
可有同学就问了,公有云都会在全球/全国布下很多“Region”,每个Region又各自包含多个AZ(可用区),而每个AZ,又由多个数据中心组成。这本来不就是分布式的吗?
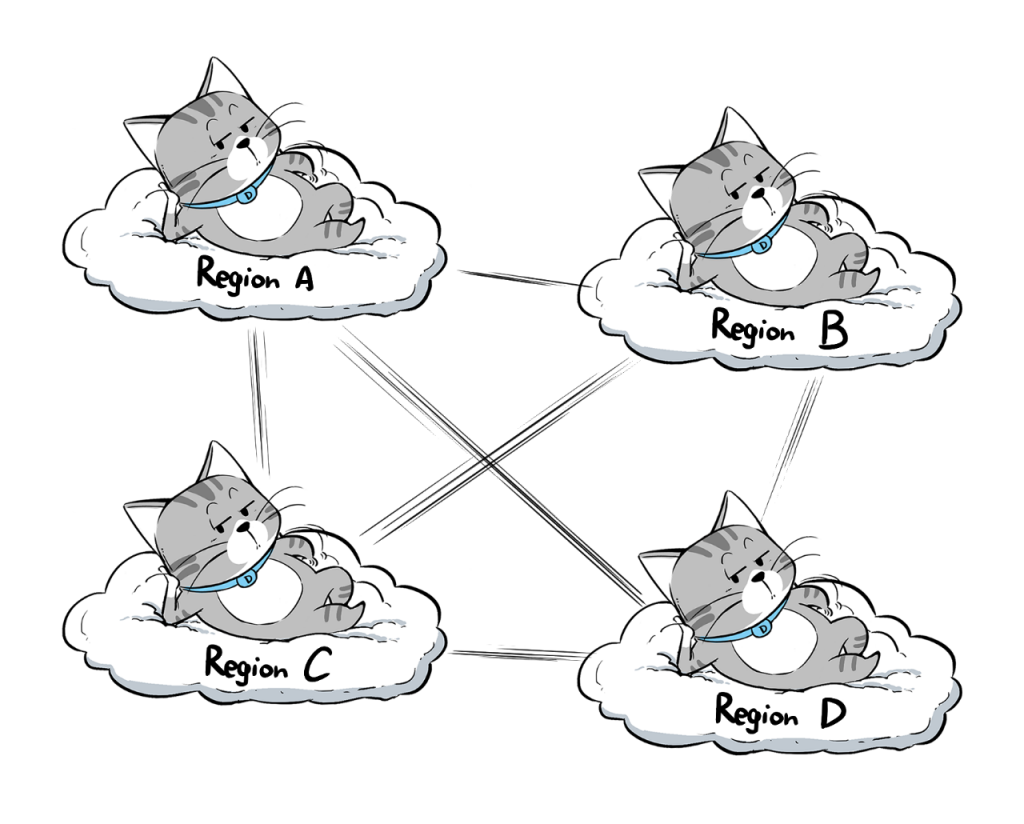
这说法没错,但「传统公有云」与正儿八经的「分布式云」,区别还是很大↓
「传统公有云」的那些Region,只能算作分布式云的中心节点,还要加上区域热点、边缘站点以及客户本地站点,这才算构成了分布式云的完整版图。
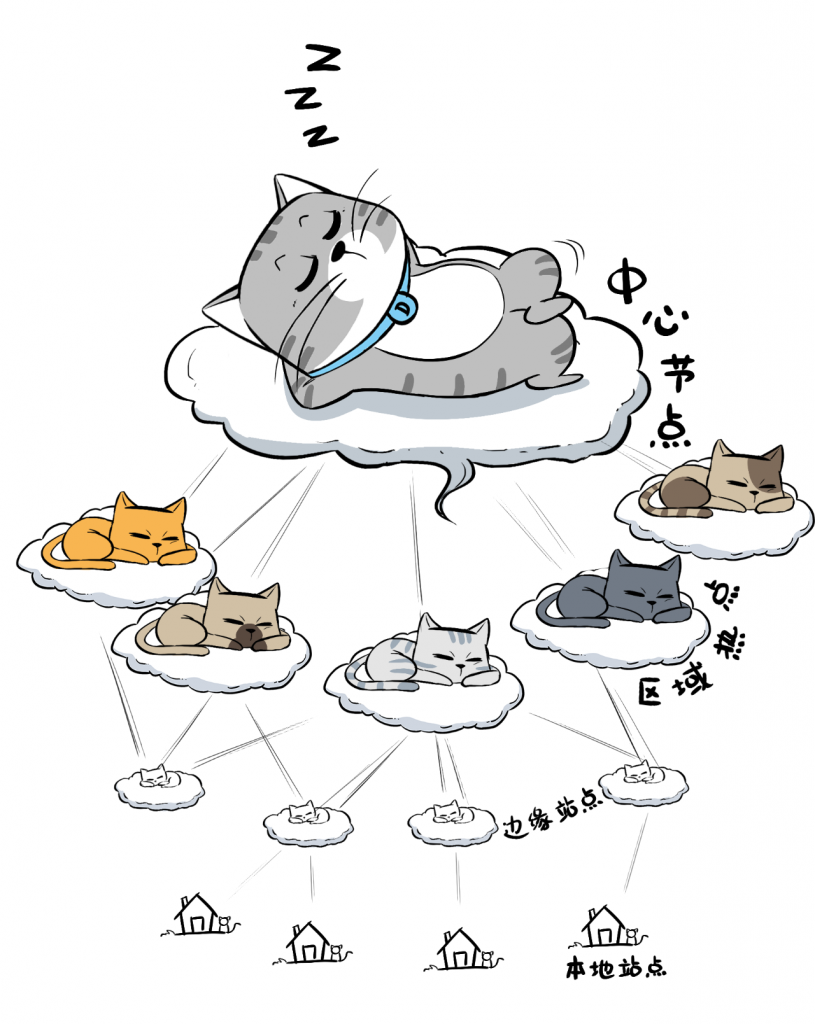
分布式云的所有的节点,都是从中心云“延伸”出来,并与中心云保持“同构”,做到统一管理,协同调度。

一、为啥大家都搞分布式云?
说白了,还是用户需求倒逼的。
首先,各种新兴业务,需要提供更低的延迟指标,或者更接近业务现场的算力支持。同时,这些广阔而分散的站点,还需要统一的管理和协同。

第二,随着云计算进入toB行业的深水区,每一个公有云巨头不能忽视客户对混合云、专有云、私有云的需求。
传统专/私/混合云的目标,是满足监管需求、资源的可控性、独占性以及本地业务的就近服务能力。
但实际建设中,往往都是项目制为主,周期长、标准化程度低、重复建设,建成以后,再被动滴找公有云打通。

专有云“整一坨”,公有云“选一朵”,然后再找个CMP,把他们拧在一起。最终,建成的混合云“混而不合”,连客户也深深感觉,这种方式,不香了。

公有云大厂看在眼里,急在心上:既然有些用户过不来,那我们就过去呗。
于是他们把自己的公有云技术栈下沉,向用户侧延伸,不仅要满足低延迟、就近接入的需求,连行业客户“专私混托”的需求,一并承包了。
二、分布式云应该怎么建?
首先,我们必须承认,云计算技术的潮流,一定是公有云厂商引领的。第二,专有云/私有云的建设需求,国内比国外更加旺盛。
所以探讨分布式云如何落地,拿国内公有云巨头的实践来举例更实用。
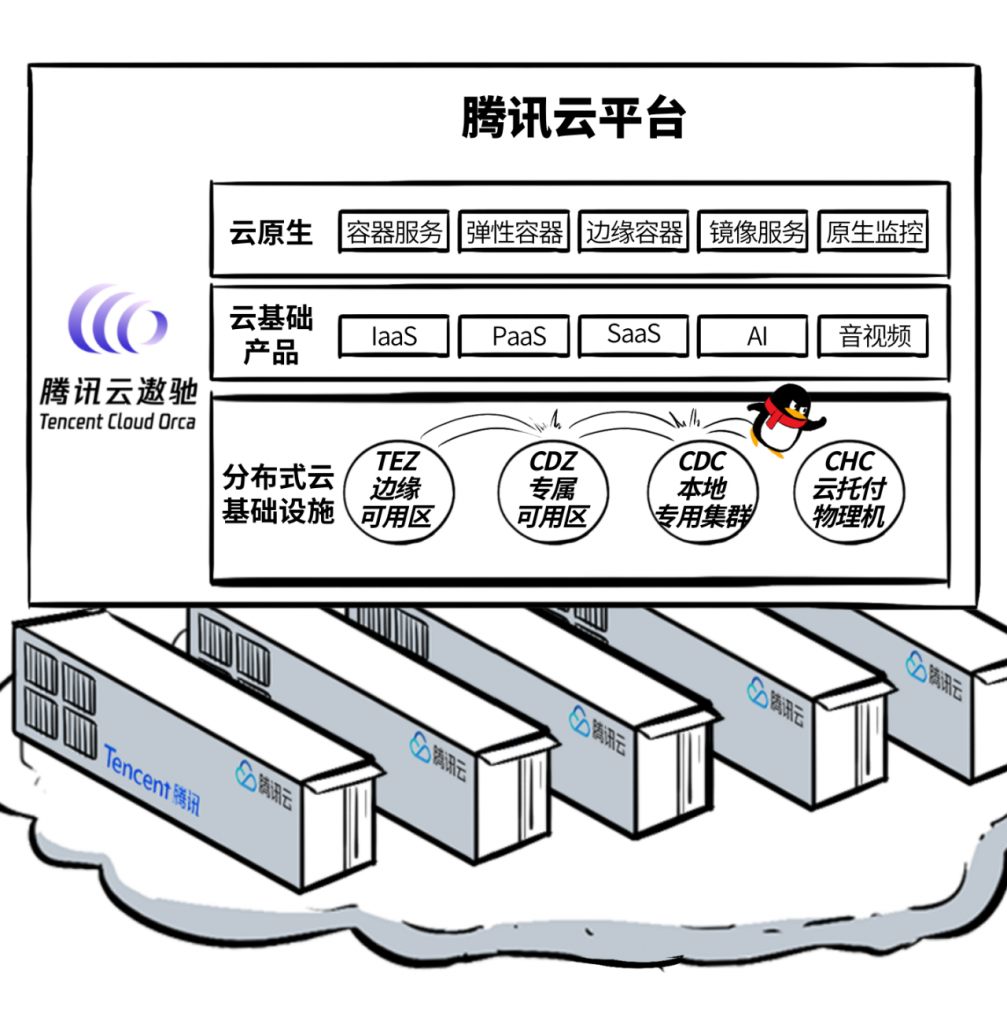
赶巧了,在2021腾讯数字生态大会上,鹅厂云来了一波齐射,重磅发布分布式云产品。

产品形态一 CDC,本地专用集群
CDC的物理形态就是个「计算存储网络」一体化的机柜,跟AWS Outposts有点异曲同工,集成了UPS、制冷、动环监控,单机柜最小只需3个服务器节点,支持多机柜扩展。
这个“大箱子”相当于是分布式云的基础设施底座。

把这大箱子“扛”到用户驻地,开箱即用:放置、上电、通网。ok,三步就绪,一个本地云节点就建成了。

CDC将鹅厂公有云的能力,延展到客户本地或者生产现场,小到工厂的智能质检产线,大到区县级政务云的节点,都能胜任。
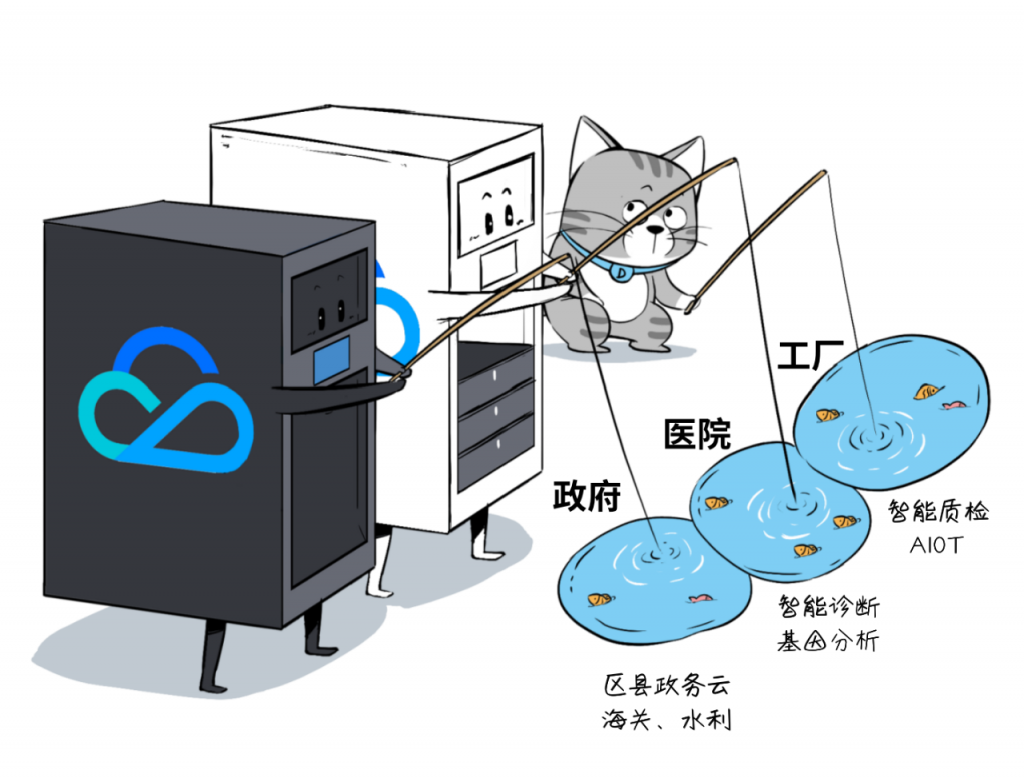
产品形态二 TEZ,边缘可用区
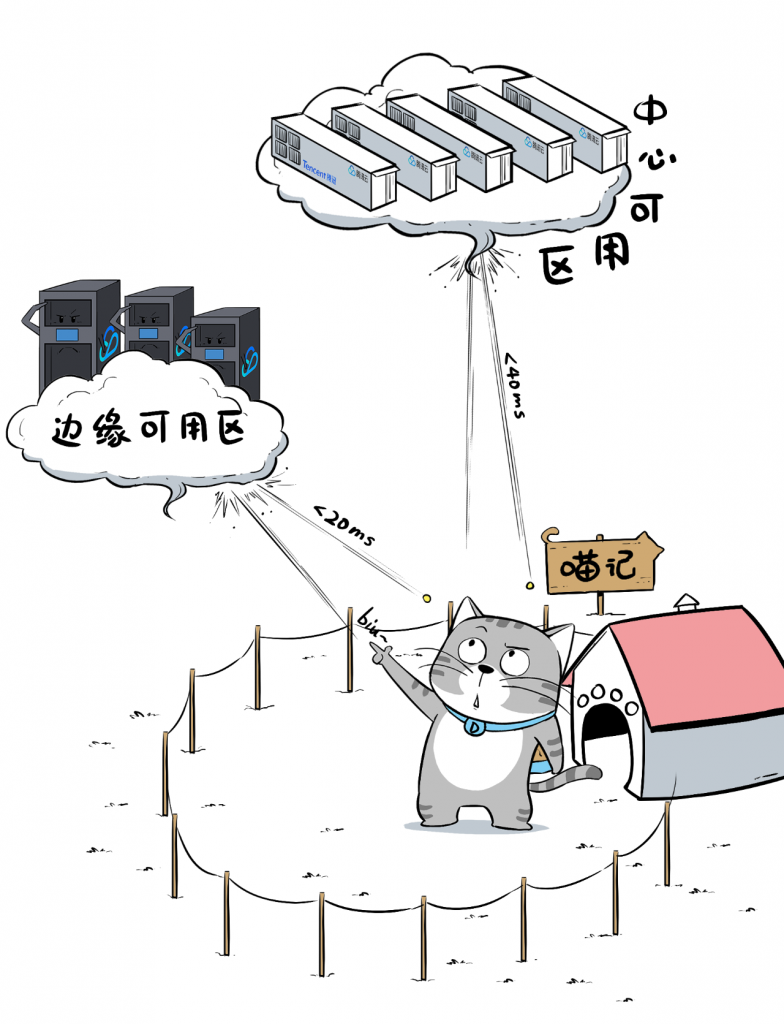
这种“可用区”跟中心Region一样,都是由鹅厂统一建设。但边缘可用区距离用户更近,延迟更低。
比如,中心可用区到终端用户的网络延迟小于40ms,而边缘可用区的网络延迟,小于20ms。
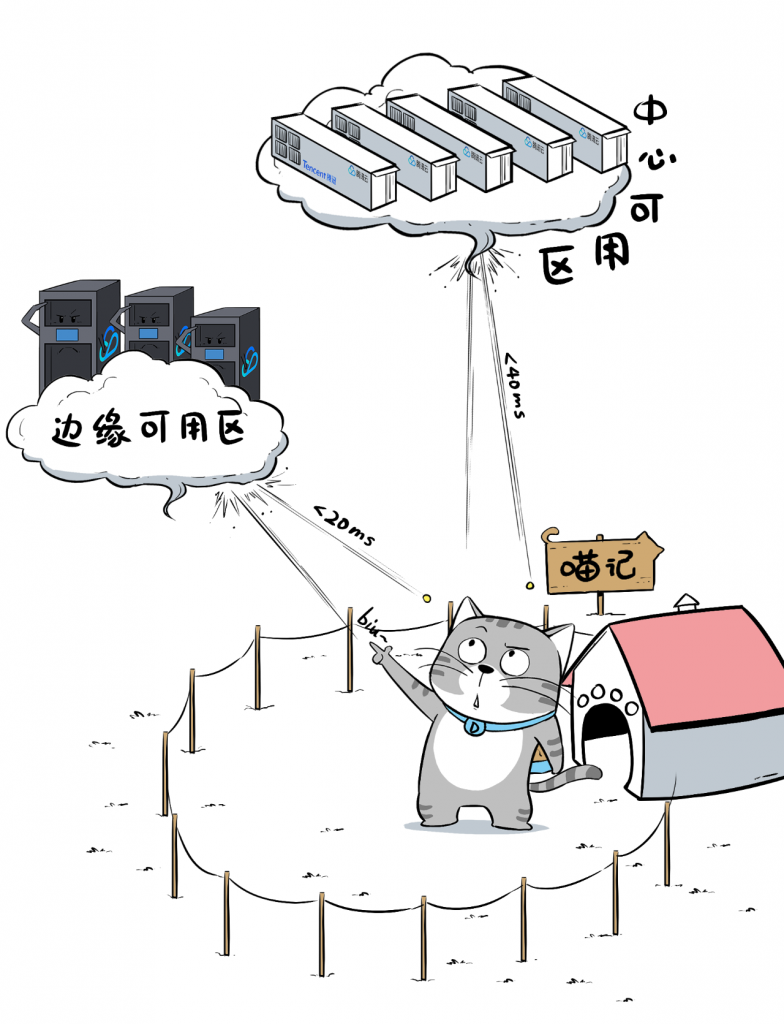
这样,针对一些延迟敏感型的业务,比如云游戏,可以在用户密集区域部署TEZ,离终端user更近,提供更好的体验。

边缘可用区以CDC作为算力单元进行部署,可以根据业务覆盖的需求,快速开通。目前,腾讯云已经部署了300+边缘可用区,还有100+正在规划之中。
产品形态三 CDZ,专属可用区
CDZ主要面向专有云客户,可以在用户自有机房、托管机房、第三方机房进行按需建设。
虽然是「专有云」,但支持与公有云同构,100+云服务按需选择。(用户可以选择TCE、TCS,也可以选择开源的TStack)

产品形态四 CHC,云托付物理服务器
这种方式最有趣,允许客户自带服务器上云。
客户可以把自己的服务器(x86或其它特种规格),托管到腾讯云的中心可用区、边缘可用区,然后,就会被“赋能”,跟鹅厂大云一样能打!
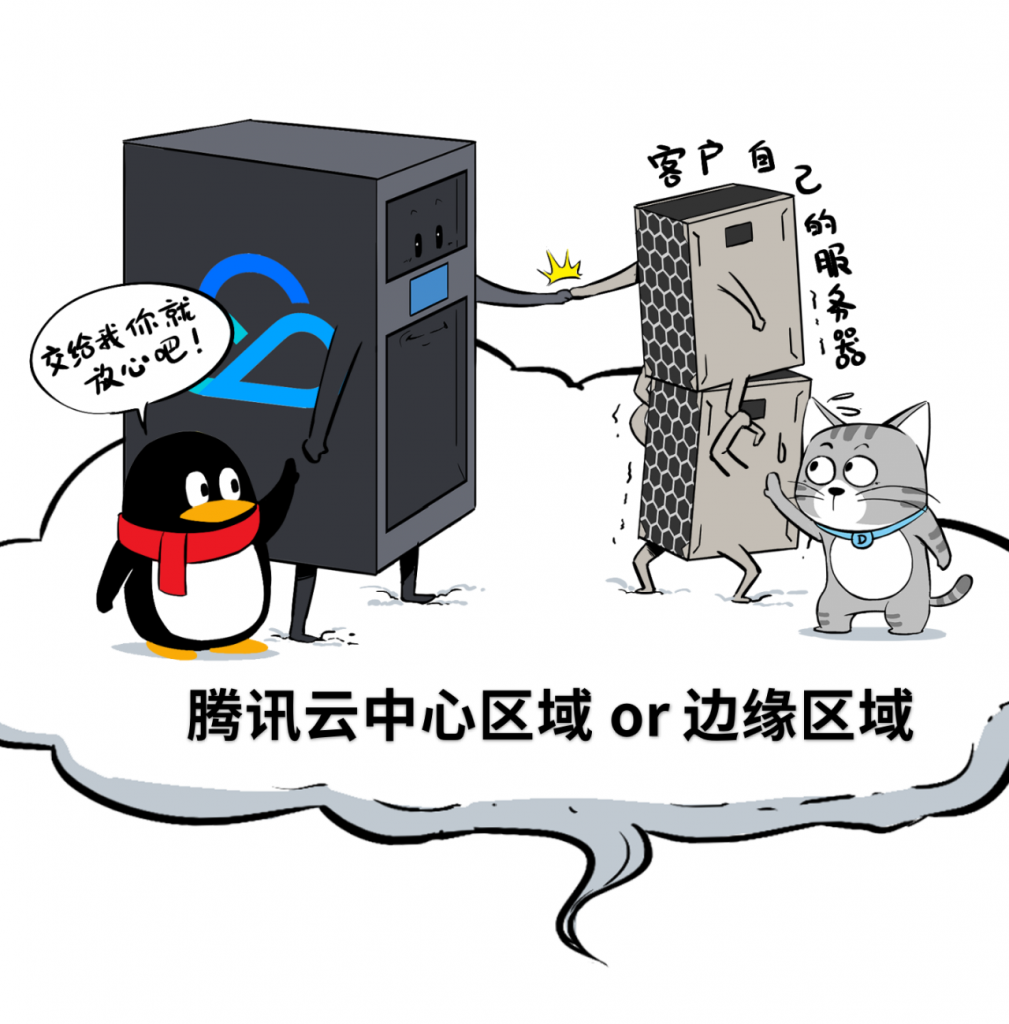
好了,有了这4大类产品,鹅厂云在物理位置上,真正实现了“分布式”。
从高大上的中心可用区,到离客户延迟更低的边缘可用区,再到按需建设和部署的本地集群、专属可用区。再加上特别贴心的,用户自带设备上云模式,即插即用。
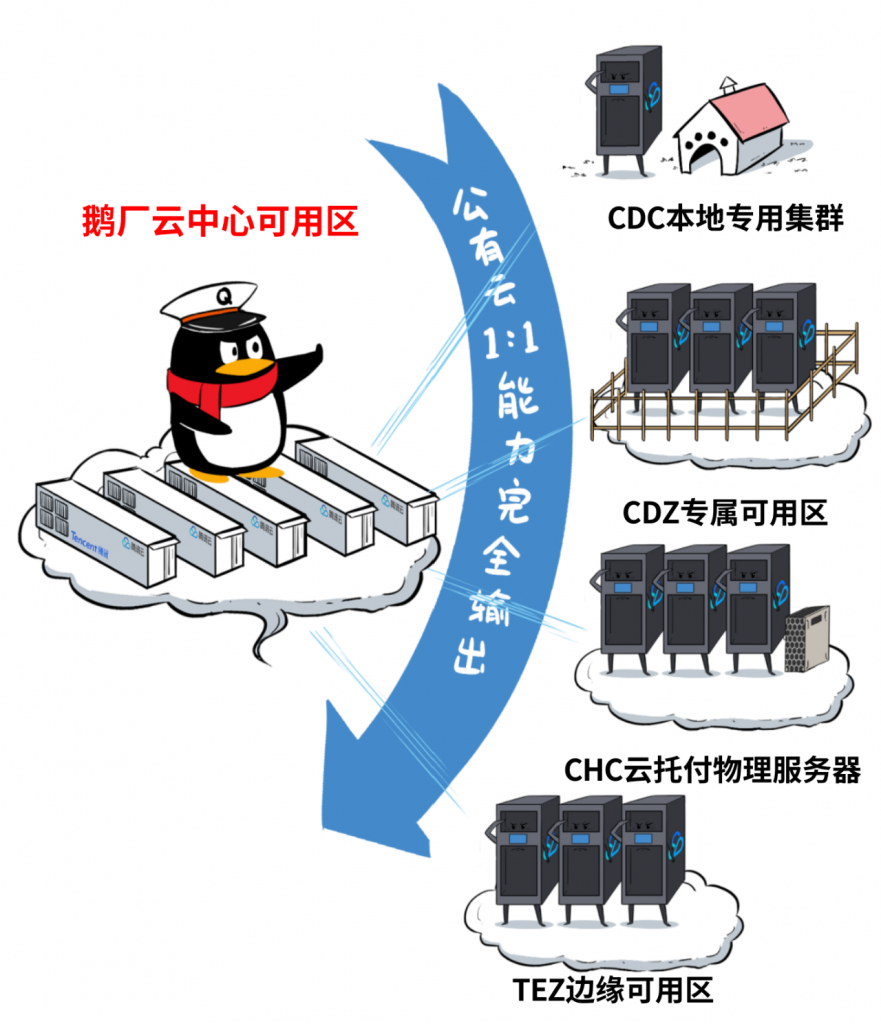
鹅厂通过这些产品组合,来确保客户在任何场景下,能够按需建云、就近入云。
至此,广大上云客户低延迟的需求、就近部署、专有/独享部署的那些诉求,都可以完美满足了。

但是,仅仅把设备东一坨、西一坨的码起来,还远远不够。
真正的分布式云,关注的不是设备,而是资源和应用,要把资源极致调度,让应用指哪打哪。真正的分布式云,是云原生化的分布式云。
遨驰,鹅厂(腾讯云)分布式云的内核
于是,鹅厂的分布式云战略,不光齐射了4大产品线,还放了另一个大招!

这个大招,就是Orca,腾讯云遨驰。
鹅厂把这个“遨驰”,定义为云原生操作系统,我认为,这才是分布式云的真内核。
“遨驰”具备超强调度能力,让整个分布式云版图上的所有资源,能够“浑然一体”,提供简单统一的管理体验和极致的资源利用率。
作为行业内首个全域治理的云原生操作系统,“遨驰”可以管理的CPU核数超过1亿,单集群支持10万级服务器,百万级容器规模…

遨驰的调度和管理能力,不仅限于VM、容器、K8S集群等资源,更可以把基于云原生架构承载的上层云能力,延伸到任意位置。
具体来说,遨驰与用户侧不同的环境、设备/资源相匹配,就会将其纳入到鹅厂分布式云管理体系下。
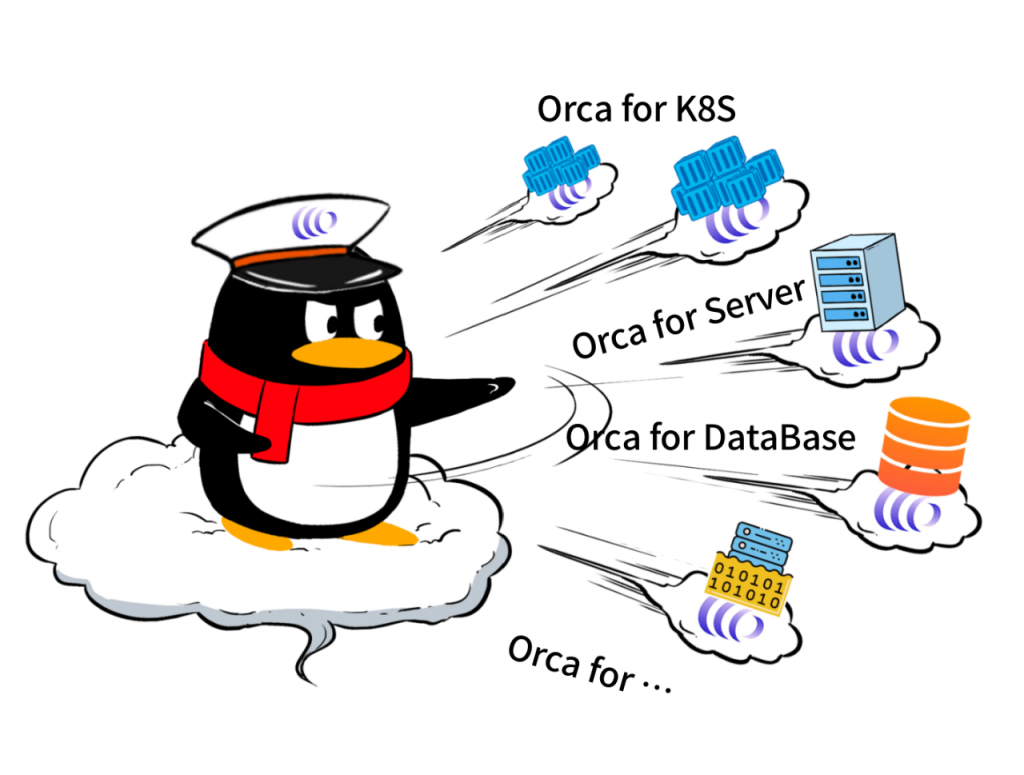
无论客户侧什么资源,只要被遨驰管理到,那么腾讯云上层产品,就能够运行在该环境中,获得云上一致体验。
同时,遨驰结合TKE分布式云中心TDCC,能够提供极致的跨云高可用,以及三倍的资源利用率提升。
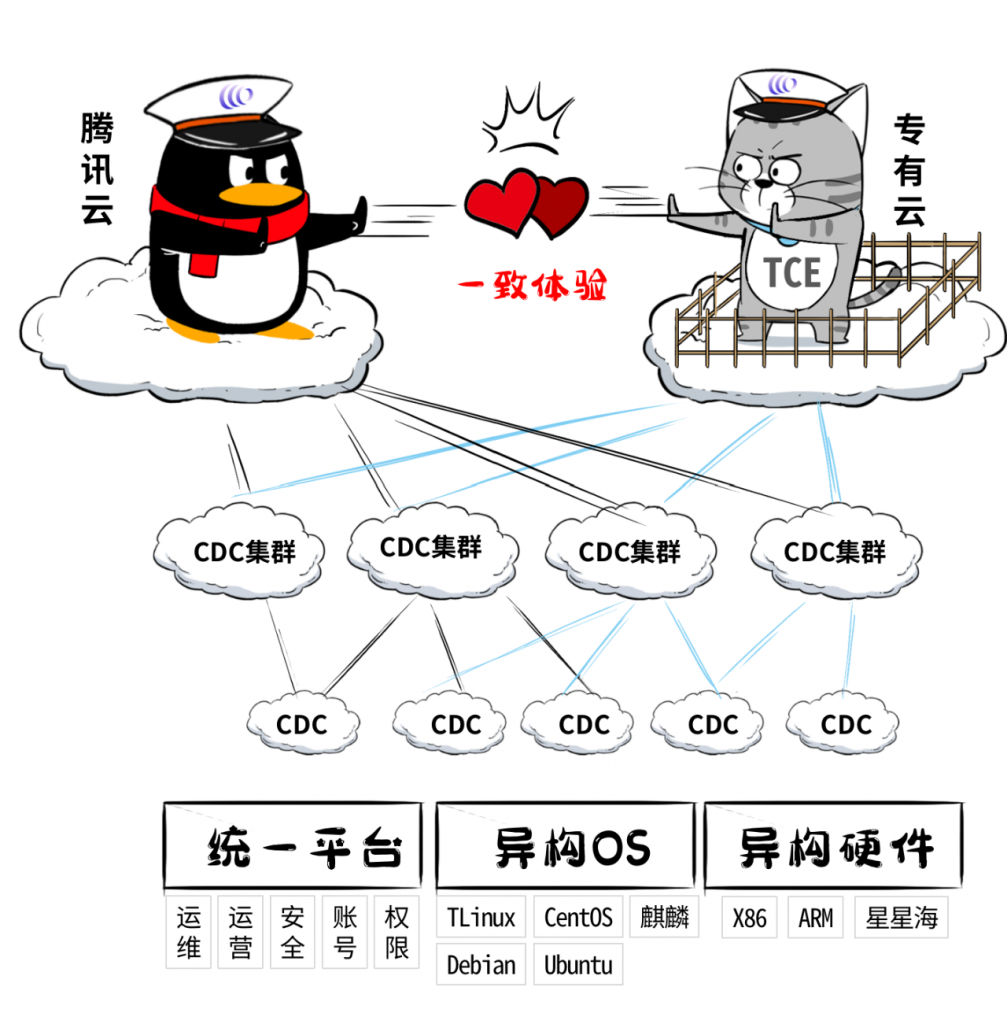
在面向行业场景落地的时候,遨驰给了用户非常灵活的选择,尤其针对有专有云业务的客户,既可以选择由腾讯云中心管控,也可以由自建的专有云TCE中心独立管控。
来看个「防疫通关平台」的典型的业务场景:
疾控中心的公卫云平台,可以作为分布式云的CDZ专属可用区,而海关和医院作为业务现场,部署CDC本地集群,低延迟高速处理本地业务。公众根据“办事路径”,与不同的节点产生互动。
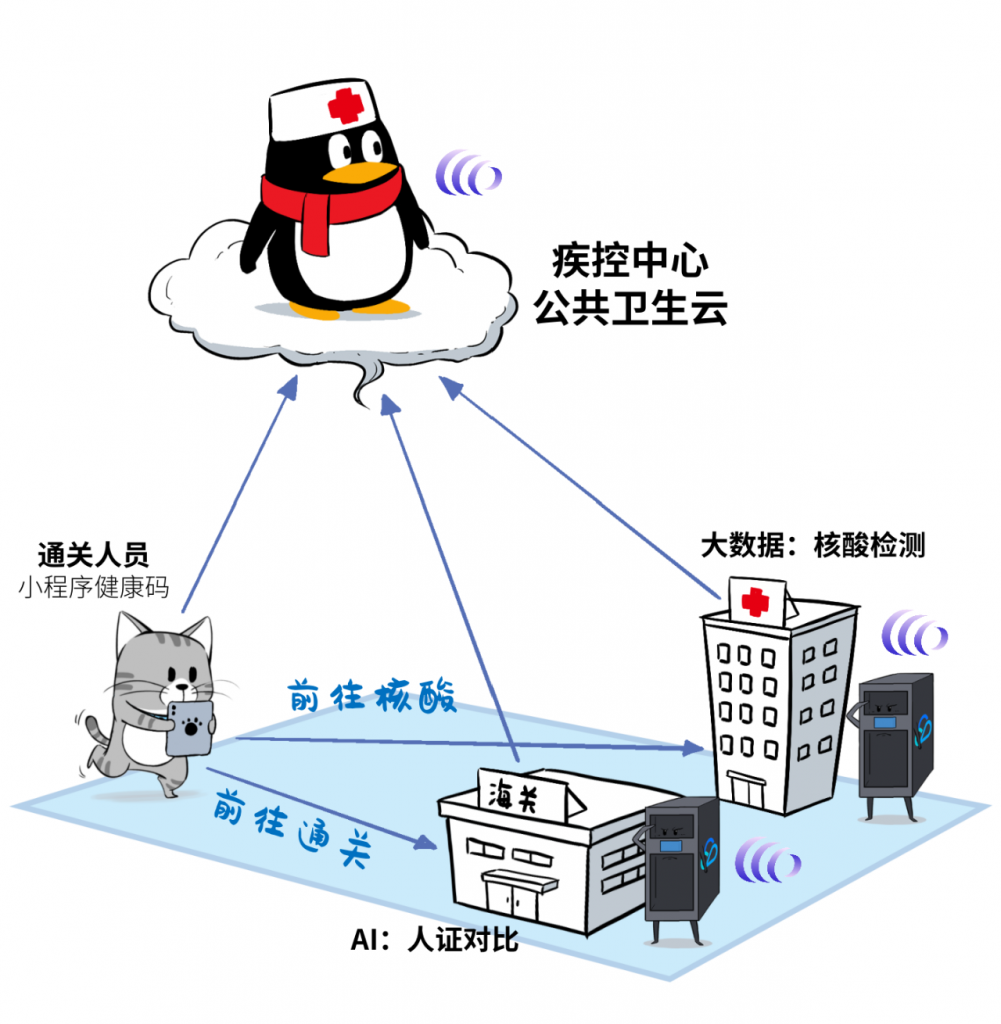
所有节点与公有云可以保持架构一致性,而遨驰则负责统一调度和统一管理。
如我们前面所说,管理端可以由腾讯云统管,也可以由疾控中心独立自治。既保留了专有云的专属性、合规性,又继承了公有云的技术红利。
那么,鹅厂分布式云的终极形态,是什么样?
其实,“遨驰→Orca”这个品牌名字,就暗藏了很多“密码”。
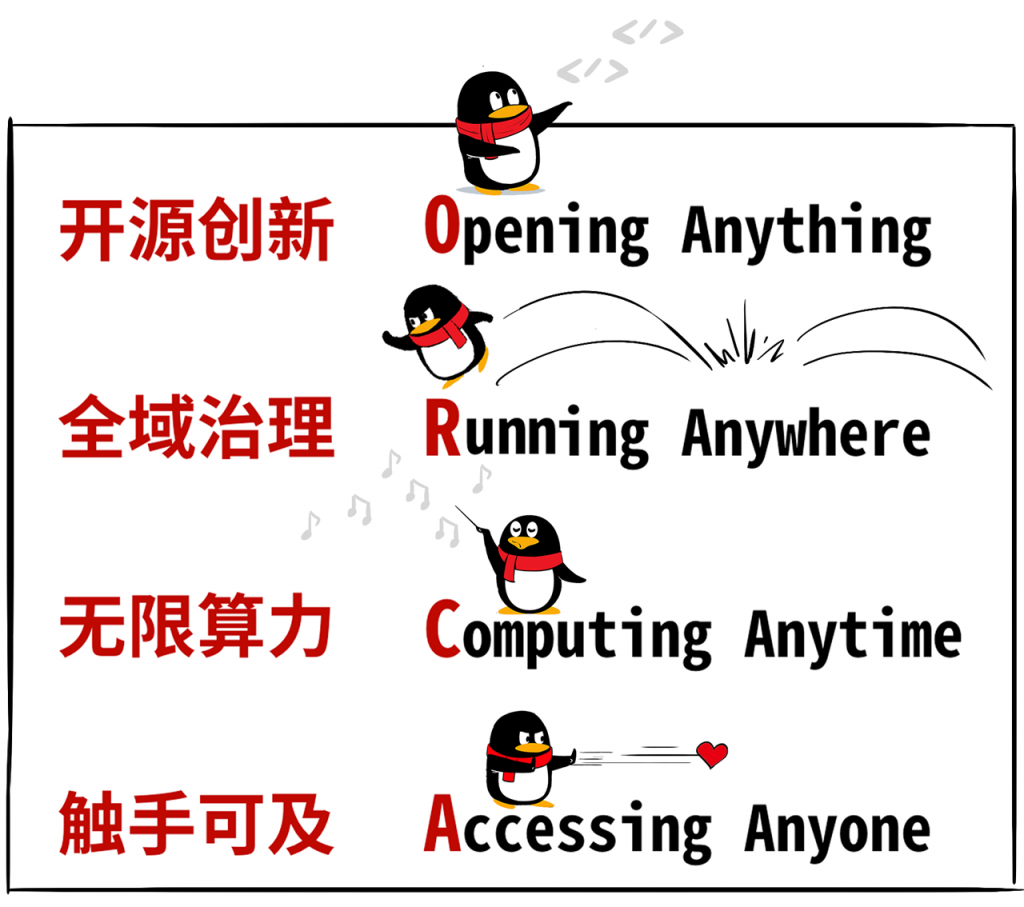
O-R-C-A ORCA遨驰,明白了啵,随时、随地、随心、随意,触手可及。
最终,四大组件(CDC、TEZ、CDZ、CHC)+ 遨驰云原生操作系统,让资源无处不在、调度无处不在、应用无处不在、接入无处不在!